原文地址:https://zhuanlan.zhihu.com/p/21442500
第一讲:Python爬虫|Python爬虫入门(一):爬虫基本结构&简单实例
第二讲:Python爬虫|Python爬虫入门(二):请求
第三讲:Python爬虫|Python爬虫入门(三):解析
第四讲:Python爬虫|Python爬虫入门(四):储存
————————萌萌哒的分割线————————
本篇我们主要讲一下第一篇教程(知乎专栏)提到的解析。这次我们换一个更复杂的例子,主要教一下大家如何使用审查元素找到我们需要的数据。这只是一个初步的对于HTML解析的方法,更多奇怪的问题,我们会在之后的教程通过实例一个一个深入探讨。
今天我们的示例网页是:巨潮资讯网,我们的目标是获取所有的股票代码和对应的公司名称。
一、HTML简介
HTML是一种**标记语言**。作为“标记语言”,需要有标记符号去标记。我们简单介绍一下一些标记。
为了和爬虫更好地结合一下,我们教一下大家使用审查元素。我们打开示例网页,然后点击右键,选择“审查元素”或者“检查元素”,然后把标签都收起来,收到这样:
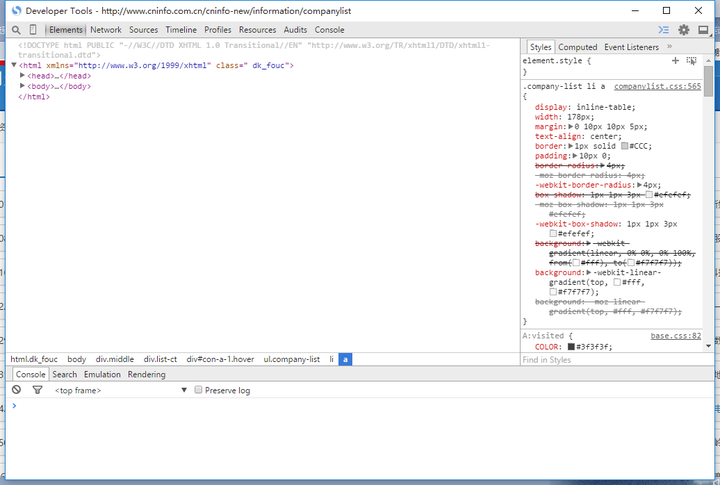
首先我们看到最基本的几个标签:
<html>, </html>
<head>, </head>
<body>, </body>
“html”定义了这个文件是个HTML,”head”定义了标题,就是这个:
“body”里面的就是网页里面的正文。后面一个斜杠加一个同样名字的标签代表这部分结束。
好的,我们继续往下。对着某一个我们需要的数据,比如
点击“审查元素”,我们会看到:
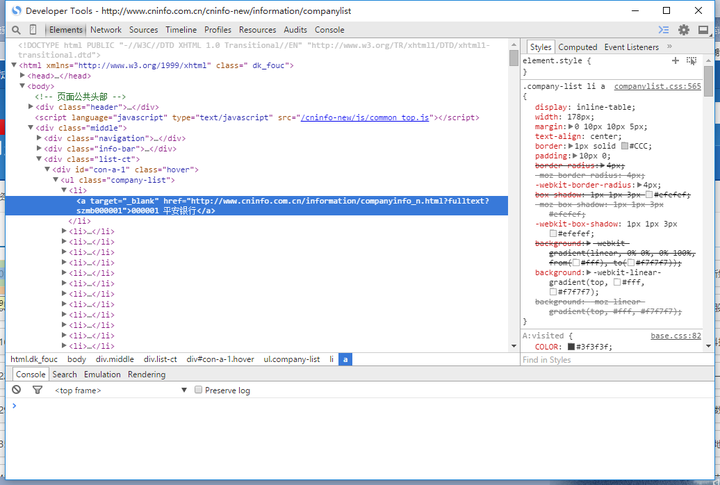
开发者工具很好地显示了HTML的层层逻辑。我们在这里列举一下我们经常见到的一些标签。(关于标签详细含义的介绍,请戳本节结束的参考资料。)
<div>; <span>; <p>;
<table>; <td>; <tr>;
<ul>; <li>;
<a>;
我们再观察一下我们需要的数据的那段HTML:
<a target="_blank" href="http://www.cninfo.com.cn/information/companyinfo_n.html?fulltext?szmb000001">000001 平安银行</a>
我们看到,在<a>标签的里面还有一些XX=”XX”的东西,这个是标签的属性。(具体的含义我们也不多介绍,如果想深入了解,请戳本节结束的参考资料。)
一些基本的概念就讲到这里。也许你会以为这还不够。这当然不够,但是对于bs4的一些基本用法已经足够了。
参考资料:W3School是一套非常好的Web开发教程。关于HTML,请戳:HTML 简介
二、bs4解析HTML
这次我们使用IDLE来编写程序。
在使用之前,你需要下载一下这个第三方库(知乎专栏)。
我们打开一个新文件:
然后按照第二讲的请求方法(知乎专栏),先把HTML请求下来:
import requests
def getHTML(url):
r = requests.get(url)
return r.content
接着,我们在审查元素里面去找我们需要的数据(见本篇第一部分)。我们接下来要做的事情是,用bs4这个强大的工具,通过前面提到的标签和标签的属性定位到某个标签。
首先我们要导入模块并创建一个BeautifulSoup对象:
from bs4 import BeautifulSoup
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
后面的这个参数是解析器。关于解析器的选择,请参考官方文档:Beautiful Soup 4.2.0 文档。我们这里使用Python自带的解析器,这样可以避免Windows下坑爹的lxml安装问题(知乎专栏)。
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
body = soup.body
company_middle = body.find('div',attrs={'class':'middle'})
company_list_ct = company_middle.find('div',attrs={'class':'list-ct'})
事实上,找合适的标签这个技能有很多简便的实现方式和技巧。但是对于新手来说,最简单的方法反而是一个一个标签定位下去。这小段代码就示例了这个过程。从代码我们可以看到,直接索引和用find方法都是可以的。find方法里面也可以加上attrs参数,然后用字典传入我们想找的标签属性。
一个小Tip:HTML的标签习惯用“-”连接,比如“list-ct”,而不是“_”,比如
继续往下解析:
from bs4 import BeautifulSoup
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
body = soup.body
company_middle = body.find('div',attrs={'class':'middle'})
company_list_ct = company_middle.find('div',attrs={'class':'list-ct'})
for company_ul in company_list_ct.find_all('ul',attrs={'class':'company-list'}):
for company_li in company_ul.find_all('li'):
company_url = company_li.a['href']
company_info = company_li.get_text()
如果我们想取出某一类标签下所有的HTML,那就用find_all方法就可以。如果我们想要某个标签属性里面的值,那么就用字典的语法索引就可以。如果我们想要标签里面的文字,就使用get_text方法。
这里我们仍然只是把结果print出来,在下一讲再说储存:
from bs4 import BeautifulSoup
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
body = soup.body
company_middle = body.find('div',attrs={'class':'middle'})
company_list_ct = company_middle.find('div',attrs={'class':'list-ct'})
for company_ul in company_list_ct.find_all('ul',attrs={'class':'company-list'}):
for company_li in company_ul.find_all('li'):
company_url = company_li.a['href']
company_info = company_li.get_text()
print company_info,company_url
我们把上面的函数拼到一起:
URL = 'http://www.cninfo.com.cn/cninfo-new/information/companylist'
html = getHTML(URL)
parseHTML(html)
运行结果:
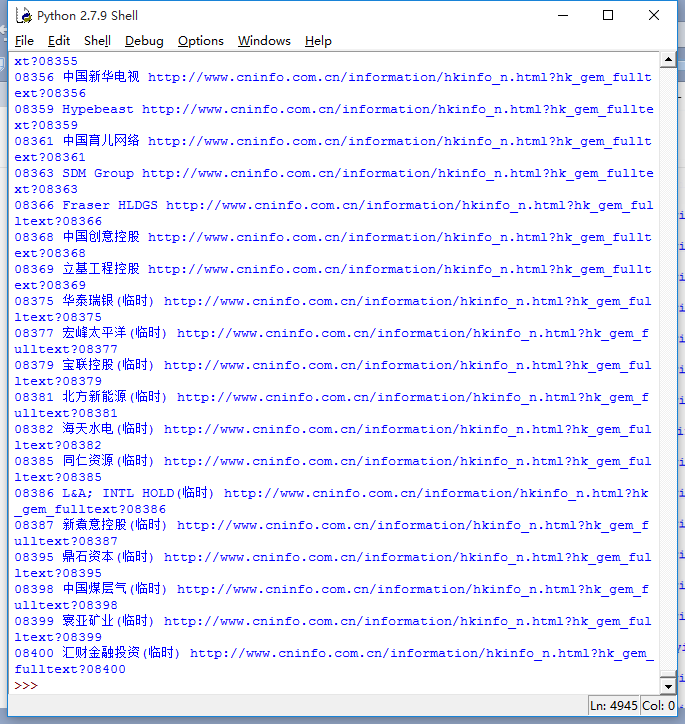
更多bs4用法,请戳官方文档:Beautiful Soup 4.2.0 文档
三、完整代码示例
import requests
from bs4 import BeautifulSoup
def getHTML(url):
r = requests.get(url)
return r.content
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
body = soup.body
company_middle = body.find('div',attrs={'class':'middle'})
company_list_ct = company_middle.find('div',attrs={'class':'list-ct'})
for company_ul in company_list_ct.find_all('ul',attrs={'class':'company-list'}):
for company_li in company_ul.find_all('li'):
company_url = company_li.a['href']
company_info = company_li.get_text()
print company_info,company_url
URL = 'http://www.cninfo.com.cn/cninfo-new/information/companylist'
html = getHTML(URL)
parseHTML(html)
————————萌萌哒的分割线————————
非商业转载注明作者即可,商业转载请联系作者授权并支付稿费。本专栏已授权“维权骑士”网站(http://rightknights.com)对我在知乎发布文章的版权侵权行为进行追究与维权。
项目联系方式:
- 项目邮箱(
的邮箱):zhangguocpp@163.com
- 项目网站:http://www.xmucpp.com/(修复中)
- 项目GitHub:China’s Prices Project at Xiamen Univerisity (CPP@XMU)
- 项目专栏:China’s Prices Project – 知乎专栏
- 项目知乎账户:
- 项目公众号:xmucpp2016(XMUCPP)